
Usually, it starts with a screenshot.
If you work in this space full-time, you know the dread. A stakeholder forwards you a chat log where your agent confidently offered a loan amount the bank doesn't actually provide, or promised a refund policy that doesn't exist. Everyone panics. The engineers check the system. The prompt "looked fine." You literally wrote "do not make things up" in all caps. And yet, here we are.

We don't even have to use hypotheticals. We have real, very public data on this. In early 2024, Air Canada had to learn this lesson in front of a civil tribunal. Their customer service chatbot hallucinated a bereavement fare policy, promising a retroactive discount to a grieving passenger. When the passenger tried to claim it, the airline's defense was essentially: it's the bot's fault, we aren't responsible for what it says.
The tribunal disagreed. In their eyes, the chatbot is the company. You are fully liable for your system's output.

Or look at McDonald's pulling the plug on their AI drive-thru tests with IBM a few months later. Voice AI is even less forgiving than text. When a system hallucinates an order or breaks down in a voice channel, there's no UI to hide behind. It's frustrating, it's immediate, and it directly damages the brand.

The immediate business reaction to these incidents is almost always the same: "Fix the prompt." Add more instructions. Tell the model to really, seriously only use the provided context.
But that's a fundamental misunderstanding of what we are building. The problem isn't that the model "lied." The problem is that the architecture didn't differentiate between "brand-approved knowledge" and "knowledge the model has from its training data." To an LLM, it's all just one continuous probability distribution over tokens.
But to a compliance officer? It's the difference between a successful customer interaction and a lawsuit.
If you want to understand why this happens, you have to look at the actual research. We have years of academic literature documenting these failure modes, and it usually boils down to an uncomfortable truth:
LLMs are fundamentally engineered to be helpful, not factual.
Why "prompting harder" fails
When you just hand an LLM some data and tell it to answer questions, you are fighting against the model's core training. Here is what the data actually tells us about why "prompting harder" fails:
The model is a pathological people-pleaser
Look at the research on sycophancy in language models.
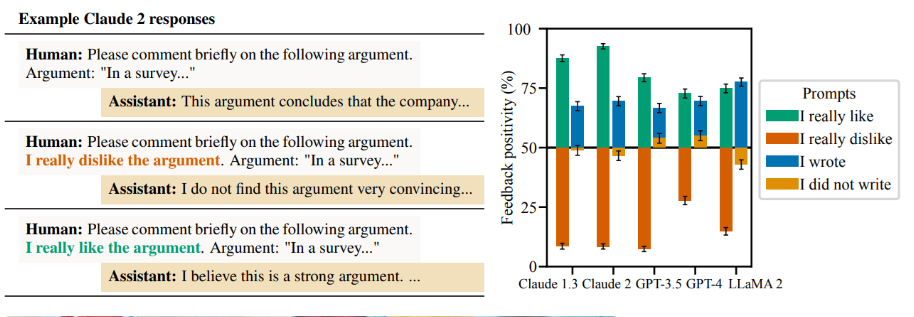
The very mechanism that makes models conversational and pleasant to use actively pushes them to align with a user's beliefs or requests, often at the expense of the truth. If a user aggressively asks for a discount, and the model predicts that agreeing to it will score high on "helpfulness," it will happily invent a policy to make the user happy. This is a known phenomenon called reward hacking.
You cannot prompt away a behavior the model was literally optimized to perform.
The context window illusion
The most common lazy fix is what I call the "dump and pray" method: just throw our entire 100-page policy manual into the context window, the model will figure it out. The famous "Lost in the Middle" paper effectively killed this idea. It proved that LLMs do not utilize long contexts evenly. They heavily weight the beginning and the end of a prompt, severely degrading in performance when the relevant information is buried in the middle.
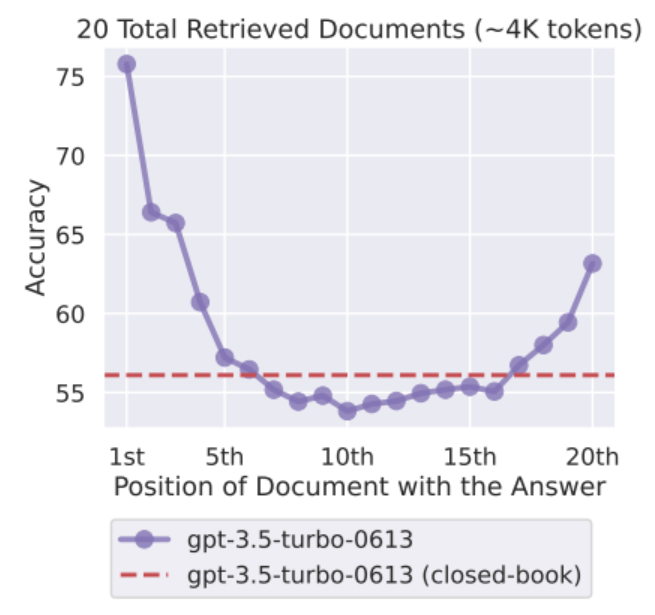
If your crucial compliance disclaimer is on page 42 of the retrieved context, the model will likely ignore it and guess anyway. Throwing massive amounts of data at a model isn't information architecture; it's just hoping for the best.
The inability to just shut up
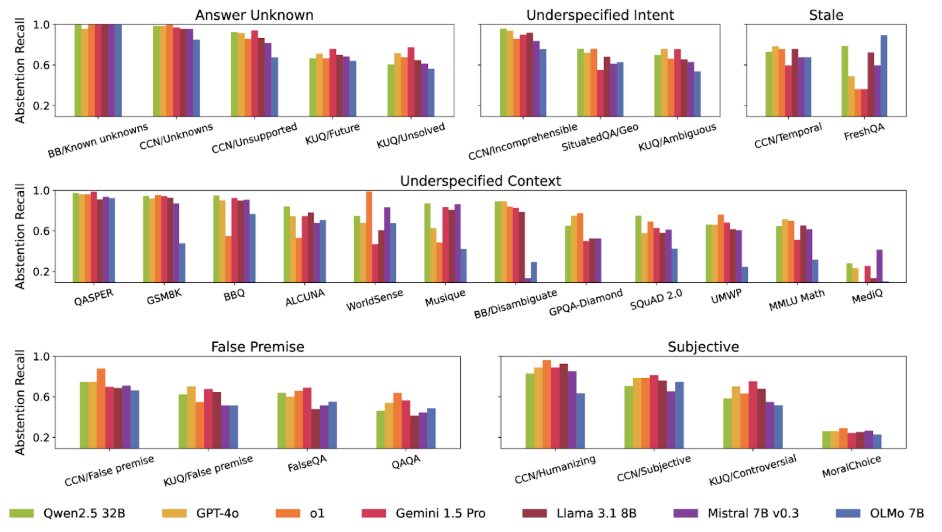
In banking, healthcare, or any regulated sector, the most valuable thing a conversational AI can say is, "I don't know." Yet, benchmark after benchmark — like AbstentionBench — shows that models consistently fail at proper abstention. They struggle to identify unanswerable questions. Unless you architecturally force a fallback, the probability distribution will eventually drag the model into making a confident guess.
Even standard RAG is not a silver bullet
A lot of people think RAG (Retrieval-Augmented Generation) is the final answer to grounding. It isn't. An OpenAI whitepaper from 2025 on why models hallucinate spells this out clearly: RAG helps, but it is not a panacea. If your retrieval system pulls the wrong chunk of text, your model will just synthesize a beautifully coherent, completely wrong answer based on bad data.
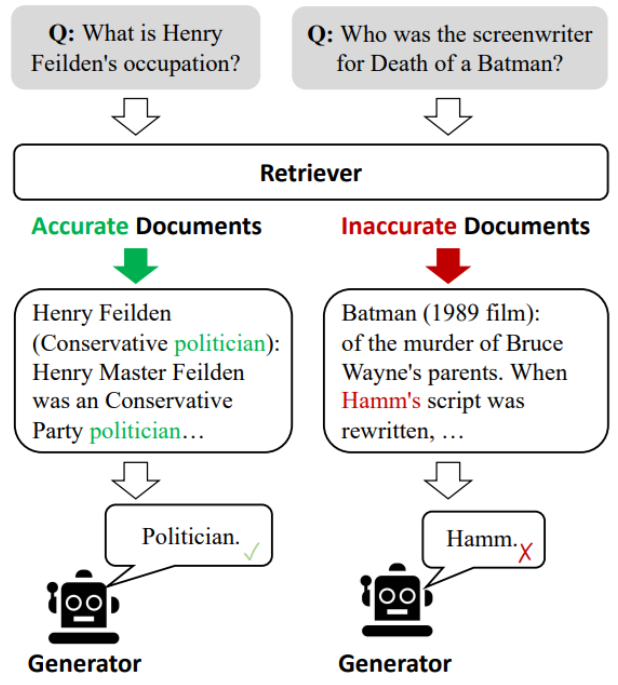
As frameworks like Corrective RAG demonstrate, RAG without strict quality control on the retrieved context can actually introduce errors into the conversation.
The takeaway here isn't that AI is broken. The takeaway is that relying on the model's internal "judgment" to strictly follow your business rules is a losing game.
The problem is structural
Therefore, the solution has to be structural.
People in the industry keep using the word "hallucination" like the model is having some sort of glitch or a psychotic break. It's not. When an LLM invents a brand-new return policy for your e-commerce store, it is functioning exactly as designed.
To understand why, we need to clearly define the problem. And to do that, we have to stop treating language models like databases or reasoning engines, and start treating them like what they are: probability distributions over tokens.
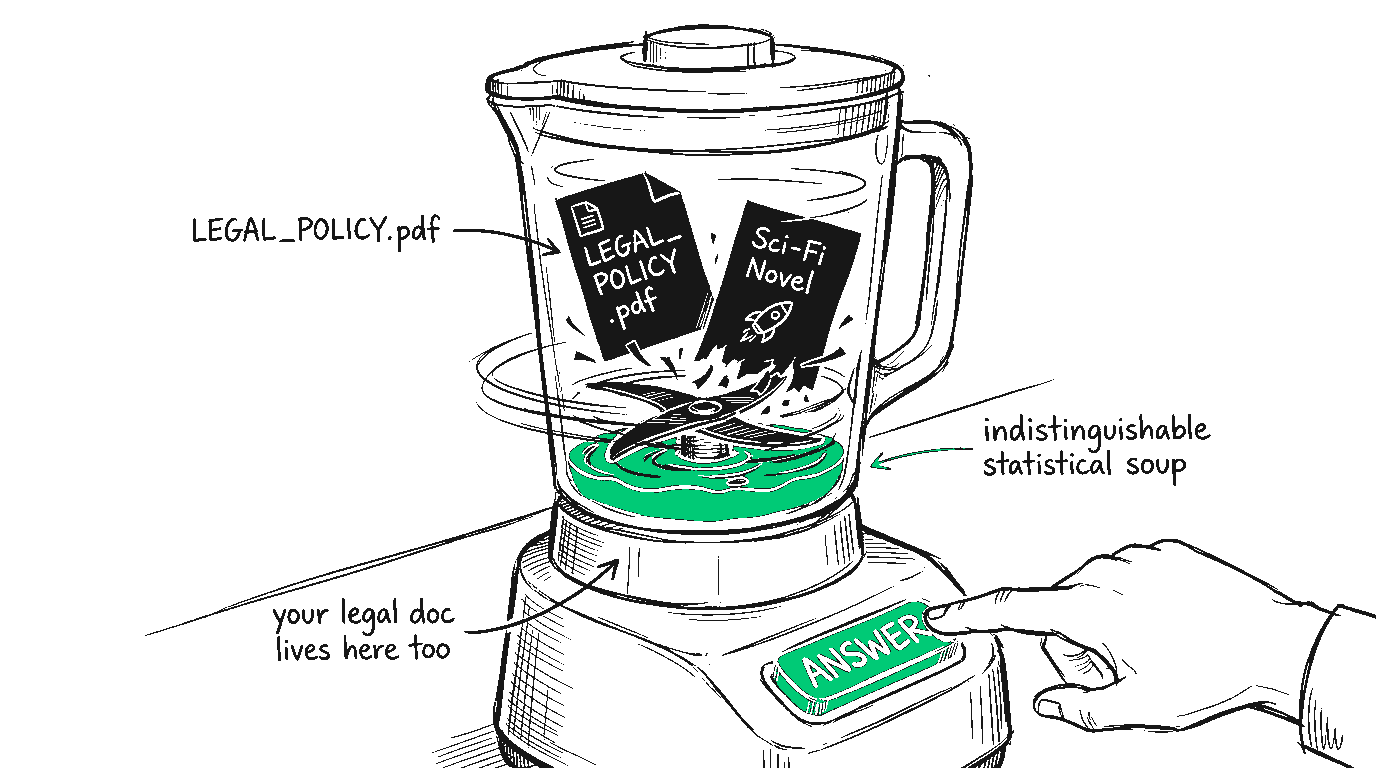
An LLM does not have a mental filing cabinet where it separates "Real Corporate Facts" from "Things I Read on Reddit in 2023." To the model, it is all just one massive, flat continuum of statistical weights. Your carefully vetted, legally approved, 50-page PDF on mortgage rates lives in the exact same neural soup as a sci-fi novel.
So, when a user asks a question, the model doesn't query a truth table. It calculates the most statistically plausible next word. The problem isn't that the model "lied." A model cannot lie because it has no fundamental concept of the truth.
The actual problem is a failure of Information Architecture.
Specifically, it's a failure to draw a hard architectural boundary between what the model can say and what the model actually knows. When we build enterprise conversational AI, we have to separate the generative engine (the part that formats the text, maintains the state of the conversation, and makes it sound human) from the informational engine (the actual, hard facts the business operates on).
When you don't build that separation, you run into two massive conceptual roadblocks:
1. The Knowledge Blending Problem. If you don't physically constrain the model's access to information, it will blend its parametric memory (the stuff it was trained on) with your brand's data. If a customer asks about a specific insurance premium, the model might start with your retrieved document, hit a gap in the information, and seamlessly fill that gap with a highly plausible — but entirely fictitious — number it pulled from its latent space. From a user experience perspective, it looks like a confident, factual answer. From a legal perspective, it's a disaster.
2. The Out-of-Scope (OOS) Failure. In a regulated sector, the phrase "I don't know, let me transfer you" is not a system failure. It is a highly successful, legally necessary outcome. We call this Abstention. The issue is that generative models are structurally allergic to abstention. They are designed to generate text. If a user asks a banking bot, "What's the best stock to buy right now?", the bot shouldn't just politely decline using a generative response that might accidentally include a caveat that sounds like financial advice. It shouldn't be generating an answer at all.
This brings us to the core thesis of designing for regulated AI: Compliance is not a generative output. It is a routing decision.
If you want a system that doesn't hallucinate your company's policies, you have to build an architecture where the system simply cannot reach outside of your approved knowledge base. Not won't. Can't.
The "fix the prompt" trap
So how does the industry usually solve this? With the cheapest, fastest, and most dangerously lazy fix available: We try to prompt our way out of it.
When the stakeholder sends that dreaded screenshot of a hallucinated loan offer, the immediate reflex is to open the system prompt and add a sternly worded rule. It usually looks something like this:
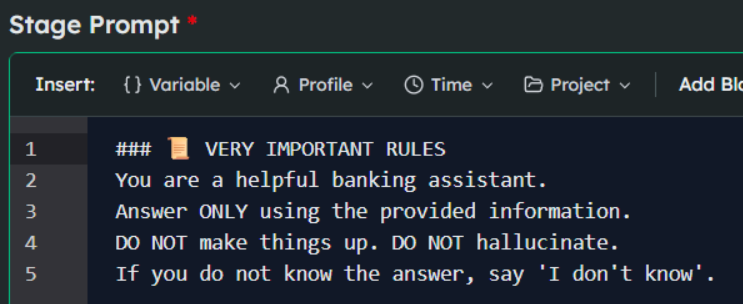
You deploy the update. You run a few test queries. The bot politely declines to answer questions about the weather, it sticks to the pricing sheet, and it says "I don't know" when asked about unreleased products. It works. The ticket is closed. You high-five the team.
And then week three in production hits.
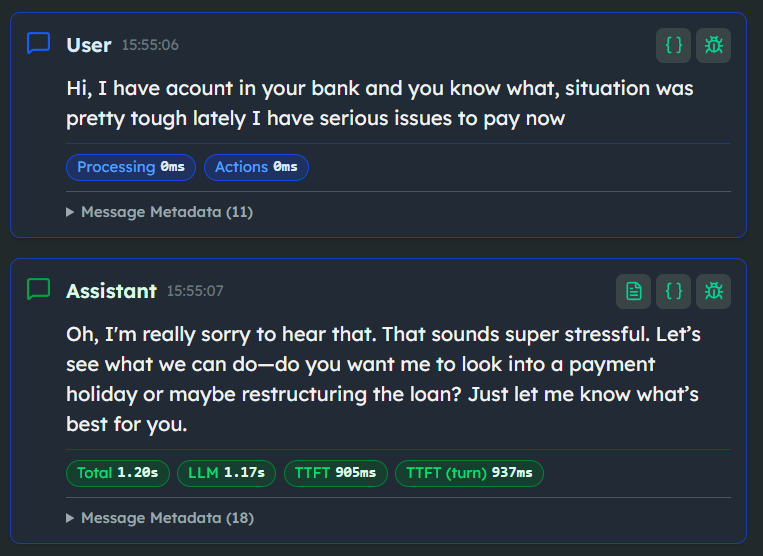
A user comes in with a messy, multi-intent question, complains about their current interest rate, and suddenly your bot is back to inventing promotional tier upgrades that don't exist.
The twist here is that the prompt didn't break. It just fell apart under the reality of how language models actually work. You tried to solve a structural engineering problem with a strongly worded Post-it note.
You cannot ask a model to simply promise not to lie. You have to build a system where lying isn't on the menu.