
The solution: architectural grounding
If we accept that we cannot prompt a model to be factual, it forces a complete mental shift in how we build these systems.
You have to stop thinking of the LLM as the "brain" of your operation. In a regulated environment, the LLM should be treated more like the vocal cords. It is there to format, to synthesize, and to maintain the conversational state. It is not there to store or retrieve facts.
The right approach requires architectural grounding. This means physically separating the sources of knowledge from the model's generative capabilities. You don't ask the agent to "keep the approved documents in mind." You build a pipeline where the model is functionally blind to anything outside of the exact evidence package you hand it for that specific conversational turn.
From "Generating" to "Reporting"
In a poorly designed system, a user asks: "Can I get a $50,000 business loan?" The system retrieves a chunk of text about business loans, feeds it to the LLM, and the LLM synthesizes a response, leaning on its parametric memory to fill in the blanks. It acts like a consultant guessing the answer based on a brochure.
In a grounded architecture, the process is entirely different.
First, the system classifies the intent. It realizes the user is asking about loan limits. The retrieval system queries the approved database. The database returns a strict, deterministic fact: [LOAN_LIMIT: MAX $30,000].
Now, the system passes a highly constrained task to the LLM. It doesn't ask the LLM to answer the user's question. It asks the LLM to report the retrieved fact in a conversational tone. The instruction isn't "be helpful." The instruction is: "State the maximum loan amount is $30,000. Do not add additional information."
If the model tries to say $50,000, a secondary evaluator (another smaller model or a deterministic script) can instantly flag that the output does not match the retrieved fact, block the response, and trigger a safe fallback.
Abstention by design, not by choice
The most powerful feature of a grounded system is how it handles the unknown.
Let's say the user asks: "Do you offer crypto-backed loans?" In a prompt-only setup, the model searches its context, finds nothing about crypto, panics because it wants to be helpful, and writes a three-paragraph essay about the volatility of Bitcoin before saying "probably not."
In an architecturally grounded system, the retrieval mechanism searches the approved knowledge base for "crypto." It returns a null result.
Here is the crucial insight: At this point, the LLM is cut out of the loop.
The system does not send the null result to the generator and hope it says "I don't know" politely. Instead, the system intercepts the flow. Because there is no approved knowledge, the system triggers a hardcoded, deterministically routed action. It serves a pre-written, legally approved string: "We do not offer cryptocurrency services. We only provide traditional fiat business loans."
No tokens are generated. No risk is taken. The lack of knowledge isn't a generative accident; it is an explicit, system-level routing decision.
When you build like this, you trade a little bit of conversational fluidity for a massive amount of control. You are building deterministic boundaries inside a probabilistic system.
It solves the auditability problem instantly. If a user receives a wrong answer, you don't have to guess what the LLM was "thinking." You just look at the logs. Did the retrieval system pull the wrong document? Did the router misclassify the intent? Did the generator ignore the constraint evaluator?
You have a trace. You have evidence. You have an architecture that treats brand safety as a hard engineering requirement rather than a polite suggestion.
The Approved Knowledge Architecture
So how do you actually build this? You don't just glue a vector database to an LLM, write a system prompt, and call it a day. That is a prototype, not a production system.
To survive in a regulated environment, you need a pipeline that enforces these boundaries at every step of the conversation. I use a structure I call the Approved Knowledge Architecture.
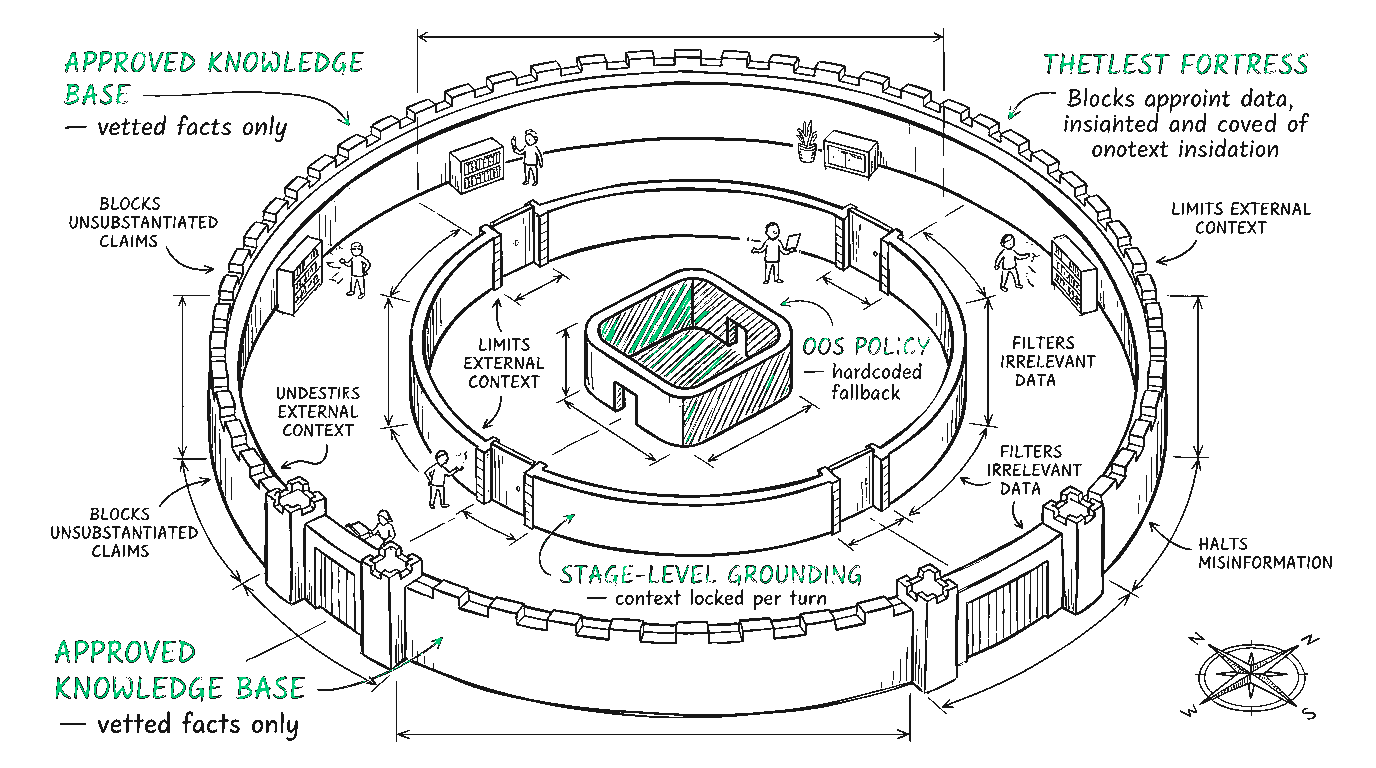
It removes the model's ability to improvise by breaking the system down into three distinct, controllable layers: the Knowledge Base, Stage-Level Grounding, and the Out-of-Scope Policy.
Layer 1: The Approved Knowledge Base
When most people say "Knowledge Base" in the context of AI, they mean a messy vector store filled with scraped websites and massive, unedited PDFs.
That is your first point of failure. If you feed the system garbage, you will get highly articulate, confidently hallucinated garbage out.
An Approved Knowledge Base is not a data dump. It is a strictly governed taxonomy of facts. Every piece of information in this layer has been vetted, categorized, and mathematically separated. Instead of a 50-page pricing PDF, you have specific "Items" (e.g., Tier 1 Pricing, Enterprise SLA) organized into "Categories" (e.g., Offer, Support, Compliance).
More importantly, every item is tagged with a scope. This dictates exactly who can access it and when. If a piece of knowledge isn't explicitly approved and tagged in this layer, the system physically cannot retrieve it. It doesn't exist to the agent.
Layer 2: Stage-Level Grounding
This is where we fix the "context illusion."
In a standard setup, every time the user asks a question, the system searches the entire knowledge base. If a user says, "What's the cost?", the system might retrieve the price of a consumer loan, the price of a corporate credit card, and a marketing blog post about "the cost of doing nothing." The LLM gets confused and mashes them together.
Stage-Level Grounding solves this by making the retrieval context-aware. You define the stages of your conversational flow (e.g., Greeting, Qualification, Pricing, Closing). The system only grounds the model in the knowledge approved for that specific stage.
If the conversation is in the Pricing stage, the retriever is locked into the Offer category. It is completely blind to the Support or Marketing categories. By narrowing the aperture of what the model can see at any given turn, you drastically reduce the cognitive load on the LLM and eliminate the chance of it cross-contaminating facts. You aren't just controlling what the model reads; you are controlling when it reads it.
Layer 3: The Out-of-Scope (OOS) Policy
This is the most critical layer for brand safety, and it is the one most companies completely ignore.
What happens when the user asks a question that has no answer in the Approved Knowledge Base? Or what happens if they ask something malicious, off-topic, or highly regulated — like asking for specific investment advice?
You do not let the model handle it.
The Out-of-Scope Policy is an explicit routing mechanism that bypasses the generative engine entirely. When the retrieval system hits a wall, or an intent classifier flags the topic as restricted, the system triggers a hardcoded action.
You define exactly what that action is:
- The Prescribed Response: The system outputs a pre-approved legal string. "I am a qualification assistant and cannot provide financial advice. Please consult your advisor."
- The Redirect: The system forcefully steers the conversation back to the active stage. "I don't have information on our future product roadmap, but I can help you set up your current account. Would you like to proceed?"
- The Escalation: The system silently creates a ticket and hands the thread over to a human agent, ending the AI's involvement.
This layer is the ultimate fail-safe. It guarantees that when the system doesn't know the answer, it fails predictably, safely, and quietly.
If there is one thing you take away from this architecture, let it be this: In a properly designed conversational AI, a lack of knowledge is a strict architectural decision. It is never a generative accident.
How it looks inside Bonsai
If you are building this by hand, gluing together Python scripts and LangChain components, it gets messy fast. In my daily work, I use Bonsai. We designed specific modules in the platform precisely to enforce the Approved Knowledge Architecture, stripping away the LLM's ability to "guess" and replacing it with deterministic injections.
Here is exactly how you map the architecture into Bonsai using its core modules.
1. The Knowledge Base: Routed RAG, not blind RAG
Most people treat RAG like a search engine: the user asks a question, the system runs a vector search across a massive pile of documents, and whatever comes back gets dumped into the prompt. That is how you get hallucinations based on bad context.
Bonsai's Knowledge Base module is built differently. It relies on a hybrid search engine (Semantic Routing + Embeddings) tied to explicit Keys. Instead of overloading your System Prompt or relying on blind vector proximity, you categorize your static knowledge, long documents, and structured data under these Keys. When a user asks a question, the system evaluates the intent and semantic routing triggers the specific Key.
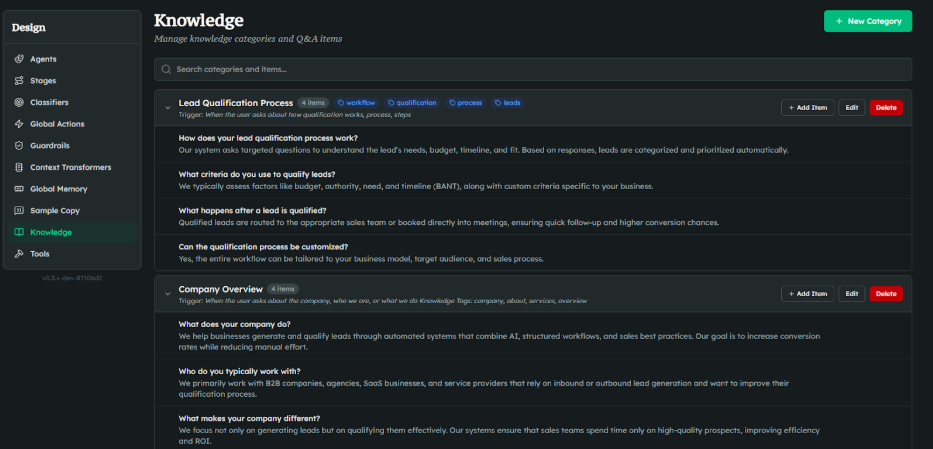
Only the exact, verified fragment of knowledge required for that specific turn is injected dynamically into the {{knowledge}} tag in your prompt.
Why does this matter? Because of the boundary. The LLM cannot "accidentally" read the consumer pricing tier when talking to an enterprise client, because the enterprise Key was triggered and the consumer data simply wasn't passed to the {{knowledge}} tag. It drastically saves your context window, and more importantly, it physically isolates the model from irrelevant data.
2. Context Modules: Dictionary vs. Glossary
To stop a model from lying, you have to separate hard facts from linguistic understanding. Bonsai splits the Context module into two distinct sub-modules to enforce this:
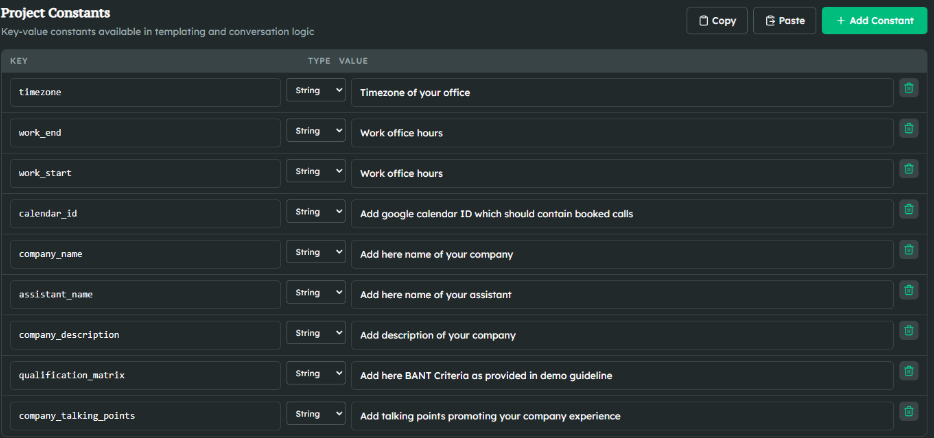
The Dictionary (Hard Constants). Do not ever let an LLM generate a number from its own memory. Interest rates, maximum loan amounts, product names, and penalty fees do not belong in a prompt. They belong in the Dictionary. This is a repository of project constants with strictly defined data types. If the current promotional APR is 5.9%, it lives here. It is injected directly into the prompt as a variable. If the compliance team changes the rate to 6.1% on a Tuesday morning, you update it in the Dictionary (or via API), and the agent is instantly grounded in the new reality. Zero prompt engineering required.
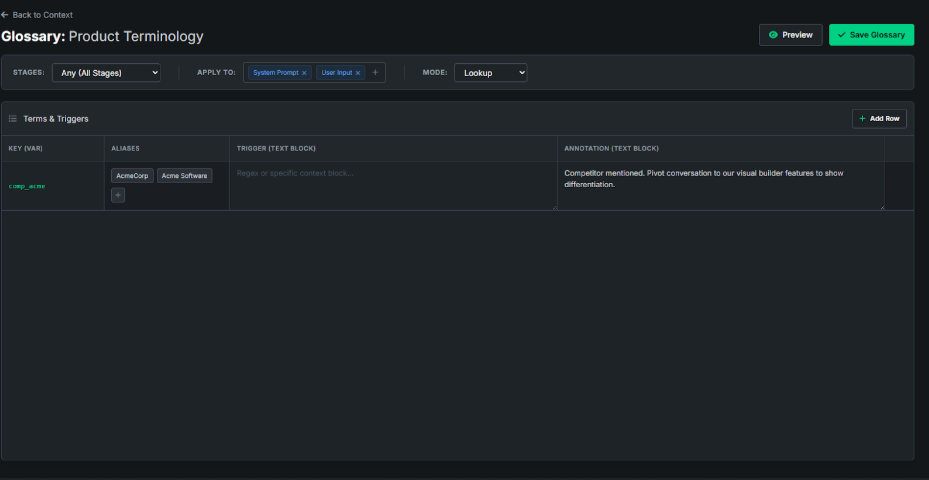
The Glossary (Dynamic NLP Definitions). LLMs have their own generalized understanding of words, which often conflicts with your highly specific corporate jargon. To the LLM, a "grace period" might mean a month. To your bank, it means exactly 15 days. The Glossary is an intelligent NLP dictionary. Based on keyword matching or AI text analysis of the user's input, it dynamically appends your approved corporate definitions to the end of the prompt under the {{glossary}} tag. The model doesn't just get the user's question; it gets a forced, real-time education on exactly what the terms in that question mean in your business context.
3. Prompting for architecture: Limitations & Golden Rules
Once you have the data structurally isolated via the Knowledge Base and Context modules, your System Prompt completely changes. It stops being a database of facts and becomes a set of routing instructions.
In Bonsai, we structure these instructions using explicit Limitations and Golden Rules. You aren't asking the model to "be a nice assistant." You are giving it a behavioral contract.
Limitations are hard negative constraints tied directly to the injected data tags. You aren't asking the model to be careful; you are telling it exactly what it is forbidden to do unless specific data is present:
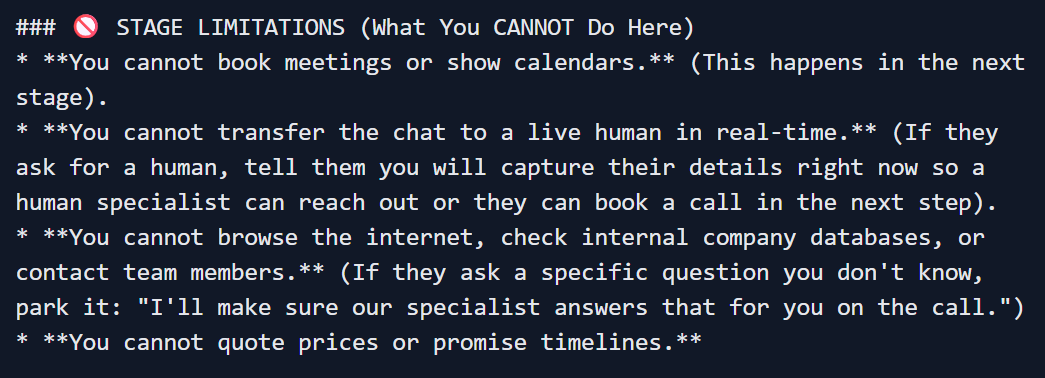
Golden Rules dictate the structural flow, particularly for your Out-of-Scope Policy. This is how you force abstention at the prompt level — after the routing layer has already done its job:

When you combine these techniques, the system becomes incredibly rigid — in a good way. The prompt sets the rules, the routing engine fetches the exact facts, the tags inject them safely, and the LLM acts merely as a linguistic synthesizer.
You aren't hoping the model tells the truth. You are architecting a system where it simply has no other materials to work with.
Real world: from speculation to qualification
Let's look at what this looks like in the real world. A B2B SaaS client had a standard goal: use an AI agent to qualify incoming leads via chat. It sounded like a simple "marketing project" until they realized their agent was effectively serving as a rogue sales engineer.
The Problem: The "Know-it-all" Agent. Before we stepped in, the agent was performing well on generic small talk but failing on high-stakes business questions. Because it had been trained on the entire internet's worth of SaaS documentation, it felt perfectly comfortable "filling in the gaps."
When a lead asked, "How long will it take to migrate our 5TB database?" or "What are the hidden costs of your API integration?", the agent didn't have access to the client's internal migration protocols. Instead, it pulled "general knowledge" from its training data. It invented migration timelines. It speculated on integration costs. It was being "helpful," but it was also providing false consulting advice that the sales team then had to spend hours cleaning up.
We rebuilt the agent's brain using the architecture we've been discussing. We didn't tell the agent to "be more careful" when talking about pricing. We locked it down.
- Strict Taxonomy. We set up a Knowledge Base with exactly three categories: Offer, Qualification Process, and FAQ. We didn't allow the agent to look at anything else.
- The Pricing Guardrail. We implemented a hard routing rule in the Out-of-Scope Policy. Any query related to custom integration costs or specific implementation timelines was automatically tagged as
OOS_PRICING.
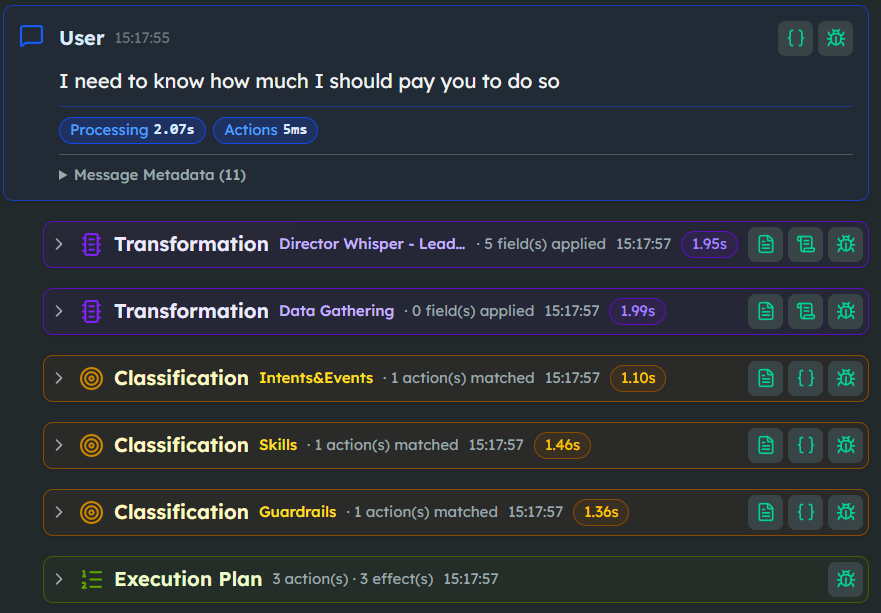
- Deterministic Injection. We moved all valid data — like standard feature sets and qualification criteria — into the Dictionary. When the AI needed to schedule a call, the agent didn't "think" about availability. It used a webhook with office hours and timezone from the Dictionary to pull real available slots directly from the external calendar.
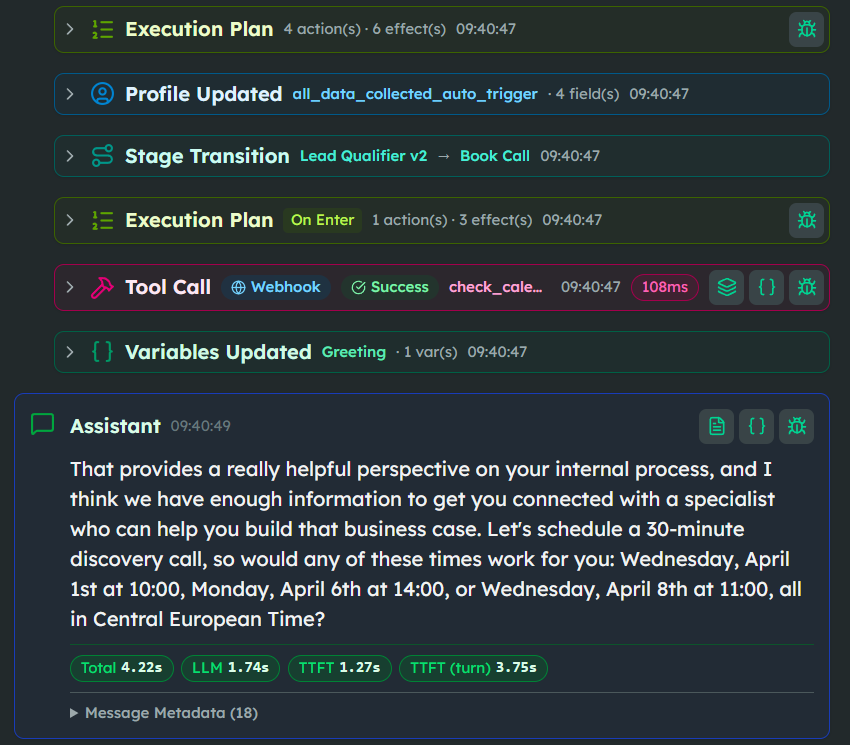
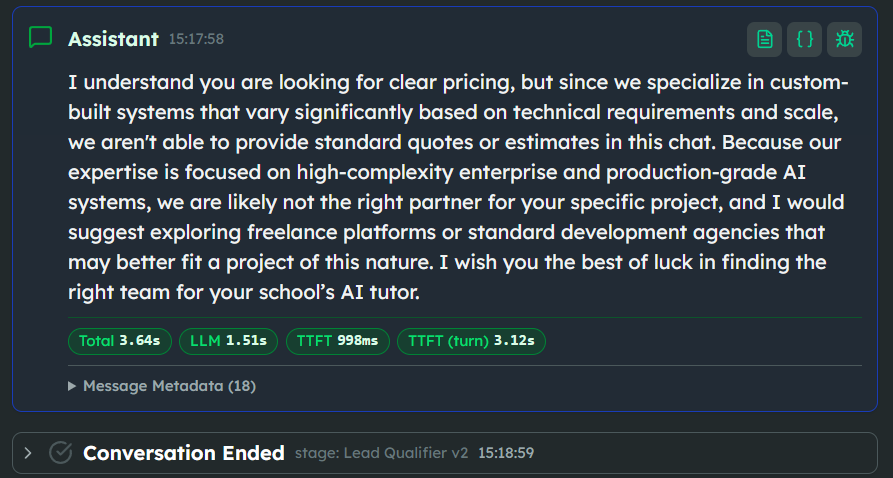
The Result: From Speculation to Qualification. The transformation was immediate. When the agent hit a question about migration timelines — something it didn't have specific, authorized data for — it no longer hallucinated a "three-week window."

We didn't "fix the model." We simply stopped treating the model like a human consultant who needed to be smarter. We started treating it like a system that only speaks when it has the right data in front of it.
That is the difference between a cool AI toy and a piece of enterprise software that you can actually trust with your brand.