
You know exactly how this goes.
The agency presents the new AI agent to the client. The demo is tightly controlled — three, maybe four turns. The user asks a question, the bot checks a knowledge base, provides a polite answer, and successfully captures an email address. Flawless. The client loves it, signs off, and it goes to production.
Three weeks later, the QA tickets start rolling in, and they are the absolute worst kind of tickets.

Nobody is reporting a 500 Internal Server Error or a broken API integration. Instead, the feedback says things like: "The agent starts acting weird after ten minutes," "It suddenly offered a refund policy we don't have," or "It completely forgot the user already authenticated five messages ago." The engineering team stares at the logs, but there's no stack trace to fix. The failure mode isn't a hard crash; it's diffuse. It's everywhere and nowhere.
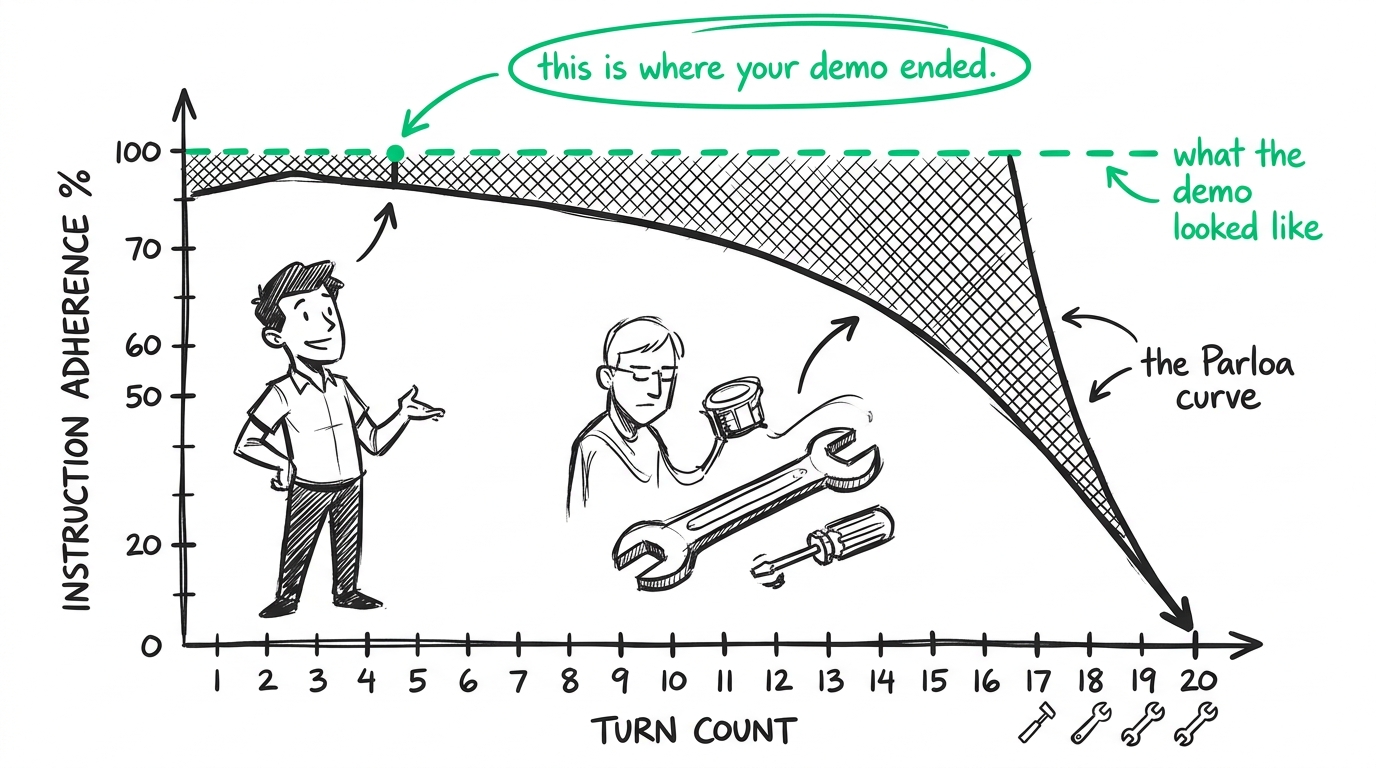
We call this conversational drift. It's the phenomenon where an agent starts strong but progressively loses the plot as the context window fills up.
This isn't a theoretical annoyance — it's a measurable hemorrhage of quality. If you look at the recent research from Parloa Labs on long-conversation performance in contact centers, they tracked exactly this in production environments. Their data shows a clear degradation curve: as the turn count goes up and the interaction gets heavier on tool-use, the agent's adherence to its core instructions steadily drops.
In a text interface, drift is frustrating. In voice AI, it's fatal. When a voice agent loses the plot, there is no visual chat history for the user to scroll up and re-orient themselves. The user's mental model of the conversation is linear and real-time. When the bot suddenly forgets the context, it doesn't look like a UI glitch — it just sounds like active incompetence. There's a reason McDonald's recently pulled the plug on their two-year automated drive-thru pilot with IBM. If a real-time system cannot reliably maintain state under the pressure of unexpected user inputs, it doesn't matter how natural the text-to-speech sounds.
The industry's default reflex is to brush this off as "hallucination" and pray that the next model update fixes it. But the root cause isn't that the model isn't smart enough. The root cause is that we are trying to solve an architecture problem with a prompt.
The Monolith: cramming everything into one text box
To understand why this happens, we need to talk about the system prompt.
The industry's default design pattern is what I call the Monolith. We take a blank text box and we just start cramming things into it. We jam in the brand guidelines, the empathy parameters, the API schemas, the edge cases, and a fifteen-step logical flowchart for every conceivable user journey. We write it in markdown. We use bold text and ALL CAPS to show the model we really mean it. We treat the system prompt like source code, assuming the LLM will compile it into a rigid set of operational laws.
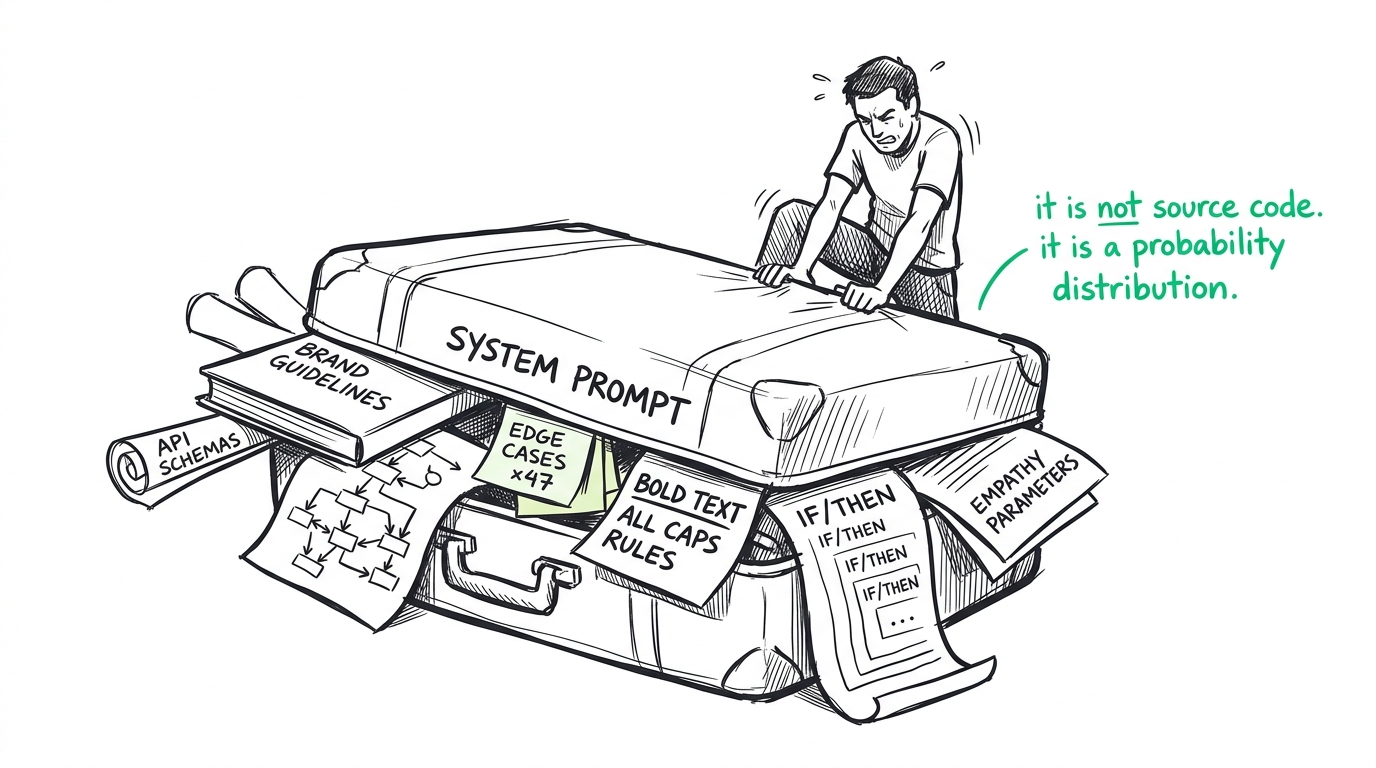
It is not source code. It is a probability distribution over tokens.
When you look at the actual mechanics of how large language models process context, the "drifting" behavior stops looking like a bug and starts looking like an inevitability.
The physics of attention
In late 2023, Nelson F. Liu and his team published the Lost in the Middle paper, which empirically proved that transformer-based models have a U-shaped attention pattern. They are highly reliable at retrieving information from the very beginning of a long context (your primary system instructions) and the very end (the user's latest message). But the middle? The middle is a swamp.
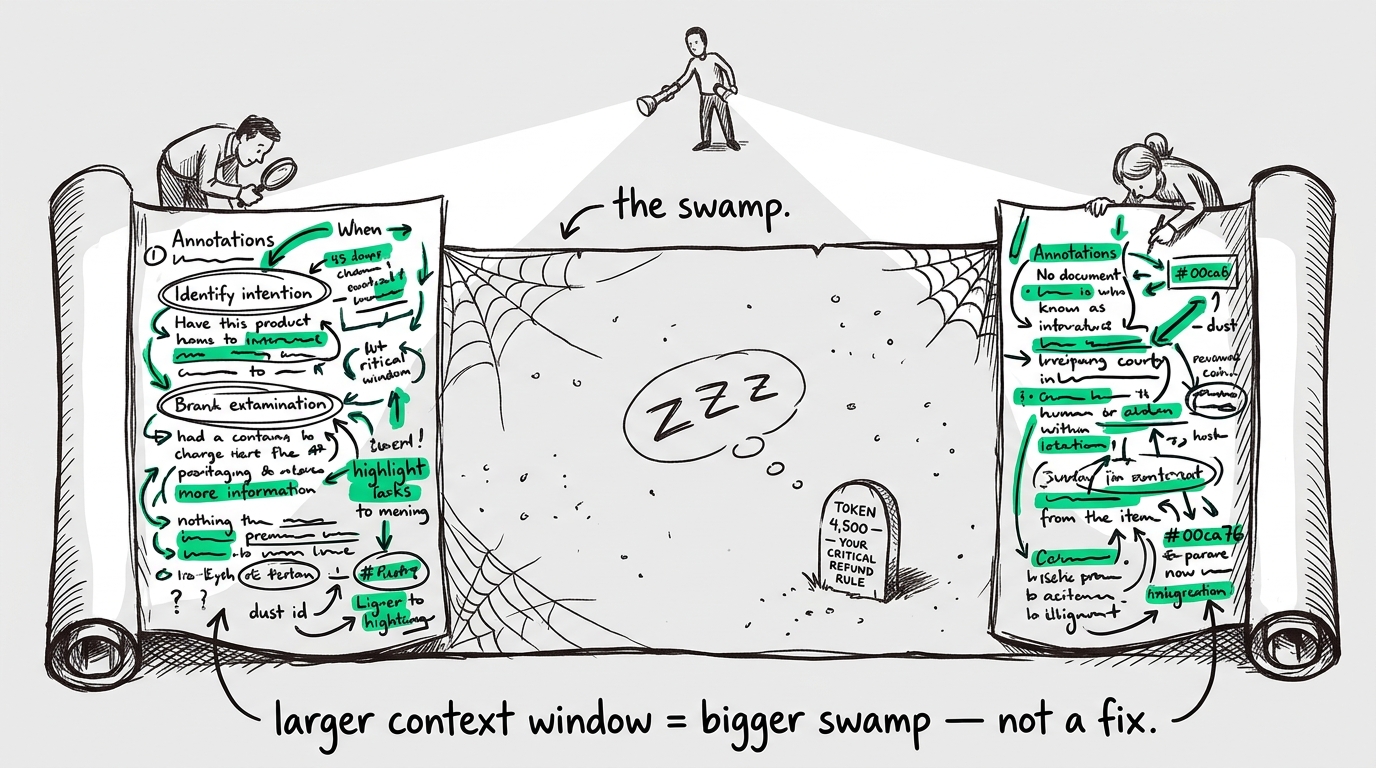
If you have a 10,000-token prompt, and your strict rule for handling a specific refund edge-case is buried at token 4,500, the model is statistically likely to just ignore it. I constantly hear people counter this by pointing to new models: "But GPT-4 and Claude have 128k or 200k context windows now!" That is entirely missing the point. A larger context window does not cure attention degradation; it just gives you a much larger, more expensive space to lose things in. You aren't fixing the drift; you're just extending the runway before the crash.
The illusion of hierarchy
We like to believe that because an instruction is labeled as system, the model will treat it as constitutional law, superseding whatever the user says or whatever a tool returns. Yilin Geng's 2025 paper, Control Illusion: The Failure of Instruction Hierarchies in LLMs, dismantles this completely. Models do not execute conditional logic deterministically. They have their own internal biases regarding how to prioritize conflicting information.
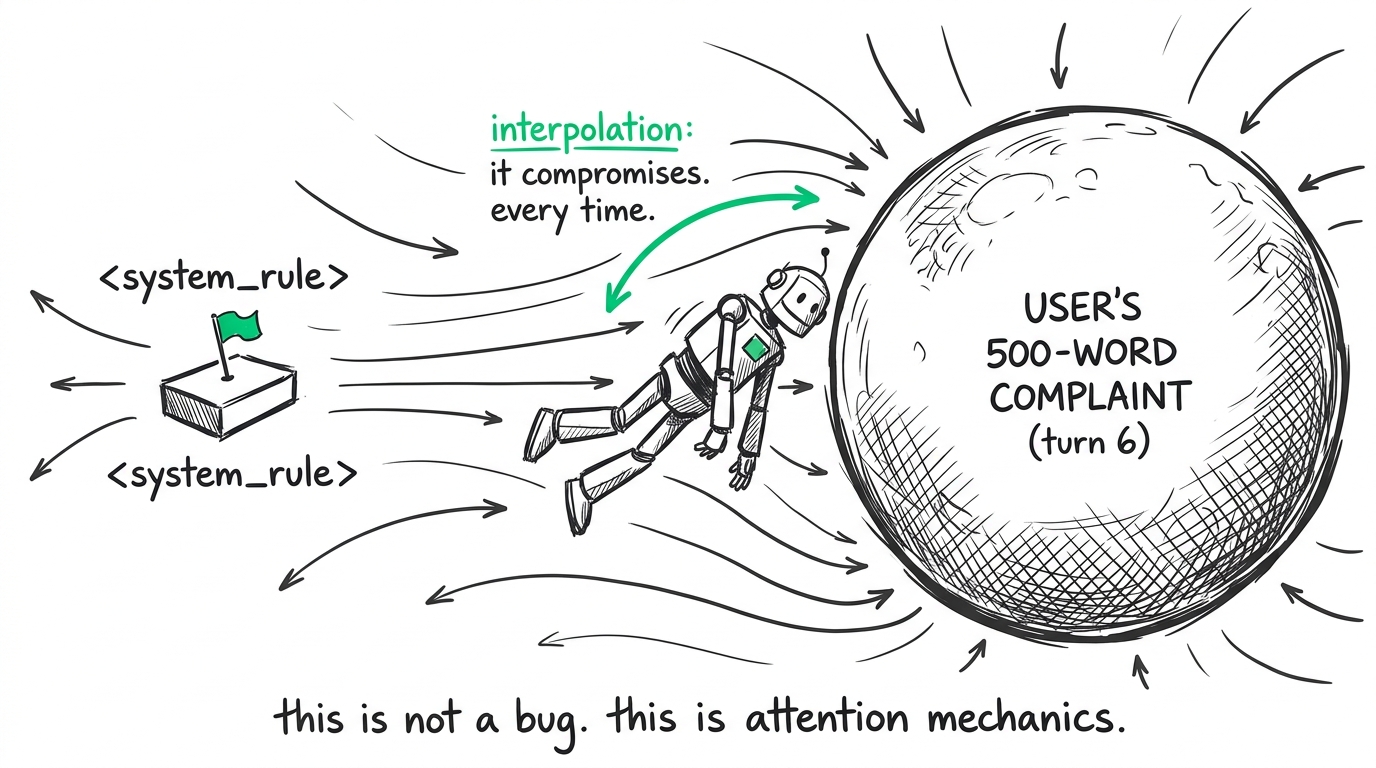
When a user sends a complex, multi-paragraph query, or when a database tool returns a massive, unoptimized JSON payload in turn six, those new tokens exert immense gravitational pull. The model doesn't strictly execute your top-level rules; it interpolates between your rules and the immediate context. It compromises. And in conversational AI, compromise usually looks like a hallucinated policy or a broken task.
A conversation isn't a monolith. It's a sequence of states.
This brings us to the core architectural flaw.
The Monolith approach treats an ongoing conversation as a single, static event. It assumes one omniscient brain can simultaneously hold the entire history of the chat, the full taxonomy of intents, and all the business logic, applying exactly the right rules at exactly the right time.
But a conversation is not a monolith. It is a sequence of distinct states.
When an agent is trying to authenticate a user, it does not need to know your shipping policy. When it is processing a refund, it does not need to know how to troubleshoot a password reset. Every single time you feed an LLM information, rules, or conversational history that it does not strictly need to resolve the immediate next turn, you are actively increasing the probability of failure. The agent isn't magically drifting — it is behaving exactly according to the noisy, bloated context it is being forced to process.
The "fix the prompt" trap
When the QA reports hit and the agent starts hallucinating return policies in production, the immediate instinct of almost every team is to open the system prompt and add more words.
This is the lazy solution. It is also the most common one.
When developers realize the model is getting confused, they try to patch the confusion with conditional logic. They start writing massive, nested blocks of IF/THEN statements directly into the prompt:
"IF the user asks about billing, THEN use a professional tone and check the billing API."
>
"IF the user is frustrated AND the refund is denied, THEN escalate to a human."
>
"IF step 3 is complete, THEN do NOT ask for the email address again."
They format it with bullet points and bold markdown, hoping the LLM will look at this text file and act like a deterministic Python script executing a switch statement.
I cannot stress this enough: this does not work. Writing pseudo-code in English and feeding it to a transformer model is not engineering. It's wishful thinking.
Here is exactly why the "mega-prompt" patching strategy collapses under its own weight:
1. Pseudo-determinism is a trap
As we just established with the Control Illusion research, models do not execute conditional logic. They weigh tokens. When you write an IF/THEN branch, you are merely increasing the probability that the model will behave a certain way. It will tend to follow your branches, which looks fine during a quick demo. But throw in a messy, contradictory user input, and the model will happily skip your IF condition, hallucinate the THEN, and invent a completely new branch of logic that you never wrote.
2. You are making the "Lost in the Middle" problem worse
By adding paragraphs of conditional instructions for every possible edge case, you are just pumping more tokens into the context window. You aren't giving the agent more clarity; you are giving it a larger haystack to lose the needle in.
3. The blast radius of updates is terrifying
When your entire agent lives in one monolithic prompt, you don't have a modular system. You have a house of cards.
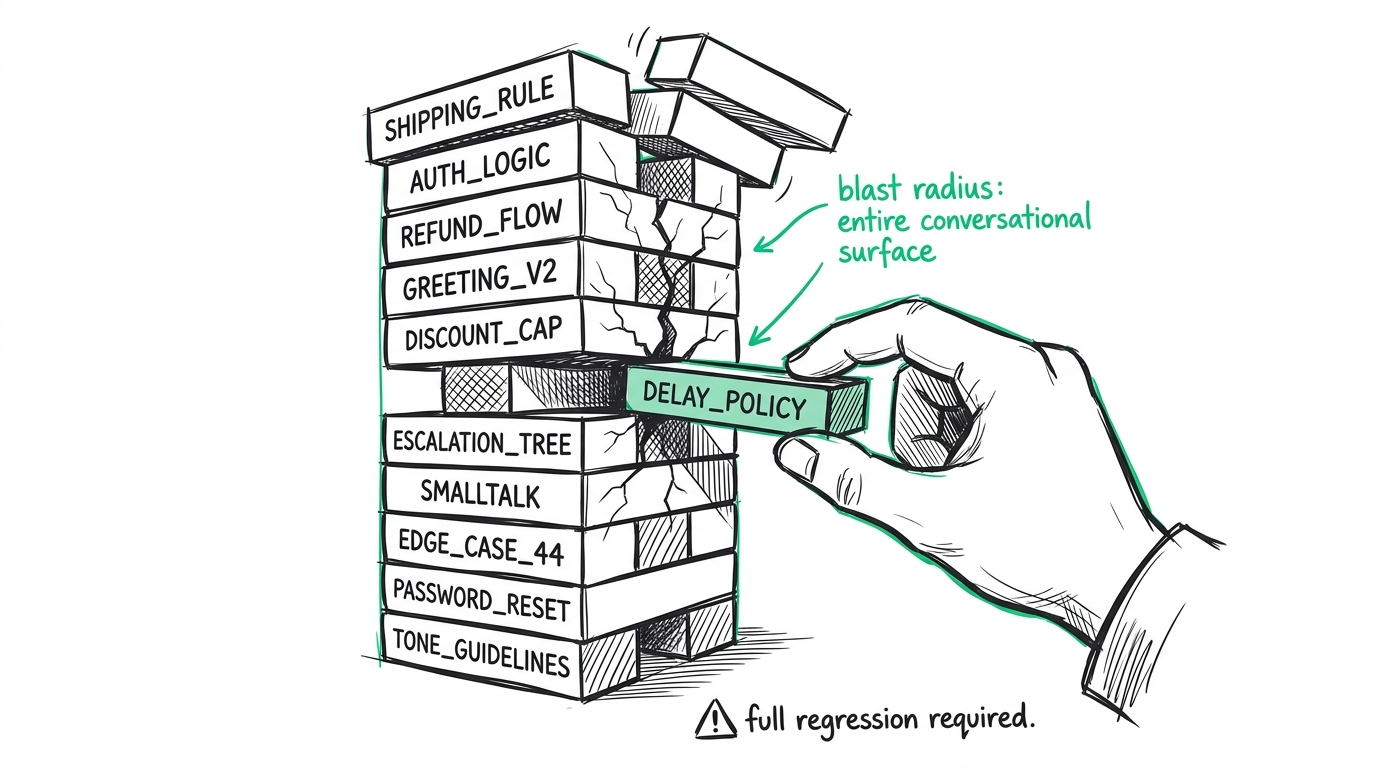
You tweak a sentence about how to handle shipping delays, and suddenly the agent forgets how to authenticate a user. Every single change requires a full regression test of the entire conversational surface area, because the model is processing all rules simultaneously.
4. You have no explicit state tracking
This is the fatal flaw. In a monolithic prompt, the system doesn't actually know where the user is in the conversation. It is just constantly re-reading the entire chat transcript and guessing what it should do next based on the vibe of the text. If the user pivots abruptly, or if an API returns an unexpected error, the LLM has to infer its new "state" from the context. It is incredibly easy for the system to lose the plot because there is no hard boundary keeping it on track.
You didn't build a state machine. You built a stressed-out intern.
Here is the plot twist most teams never want to admit: when you're patching IF/THEN logic into a system prompt, you are not programming. You are whispering to a statistical model and hoping it listens.
Language models do not have an execution runtime. They do not parse your IF condition, evaluate a boolean, and execute the THEN block. They calculate a probability distribution over tokens. When you write pseudo-code in English and feed it to a transformer, you haven't built a deterministic rule — you've simply nudged the model's weights to make a certain string of words slightly more likely to appear.
And the moment the context gets noisy — say, a user pastes in a messy 500-word complaint, or a database tool returns a massive JSON payload — the gravity of that new text overwhelms your little XML tags. The LLM doesn't strictly execute your top-level rules; it interpolates between your rules and the immediate context. It looks at your rule that says "NEVER offer a discount," it looks at the user screaming in all caps, and it statistically interpolates its way into saying, "Well, maybe just 20%."

You didn't build a state machine. You built a very stressed-out intern, handed them a 50-page manual, and threw them on the phones.
Each state in a conversation has a different objective. The "Authentication" state has strict rules and needs the user's email. The "Checkout" state has different rules and needs the user's credit card. The "Smalltalk" state requires a totally different tone and zero API access.
When you force a language model to hold the rules, tools, and context for all of these states at the exact same time, you are asking a probability engine to act as a state machine. It will inevitably fail.
To build systems that survive real users doing unexpected things, we have to stop trying to write smarter prompts. We have to start designing better information architecture. We need Context Governance — and that's exactly what Part 2 is about.