
In Part 1, we unpacked why conversational drift is structural, not stylistic — and why patching it with longer system prompts only delays the inevitable collapse. The Monolith fails because the LLM is being asked to act as a state machine, when it's a probability engine.
If the monolithic prompt is a Jenga tower, the solution isn't to tape the blocks together. The solution is to stop playing Jenga and start building a state machine.
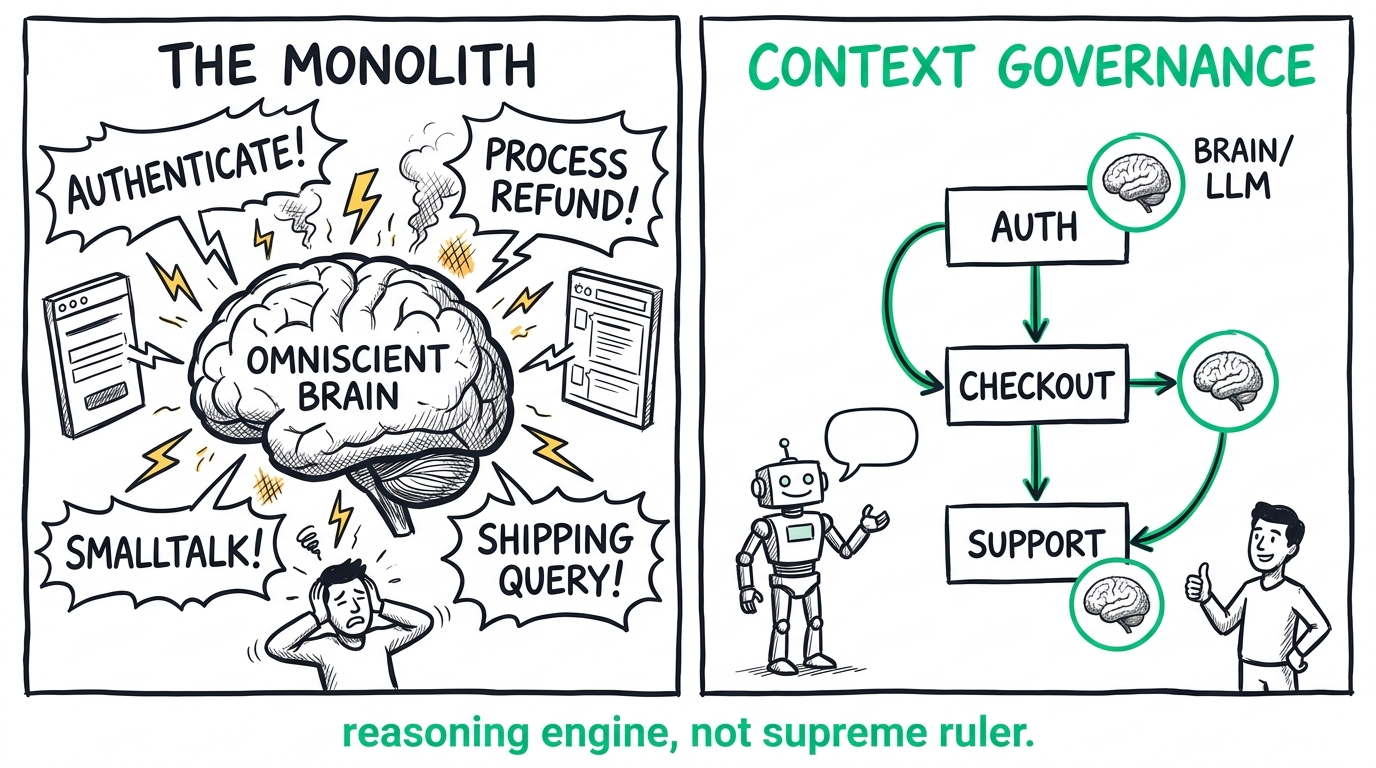
To build conversational AI that actually survives real users, we have to fundamentally change how we view the LLM. It is not the "brain" of your application that runs the whole show. It is merely a reasoning engine — a highly capable, highly erratic calculator for words. You don't let the calculator decide what math to do; you hand it a very specific equation, take the result, and move on.
This requires shifting from prompt engineering to system engineering. I call this framework Context Governance.
Context Governance: four non-negotiable pillars
Context Governance is the acknowledgement that context is a strict design resource, not a dumping ground. It's about structuring the information the LLM receives so it doesn't lose the plot. It rests on four pillars:
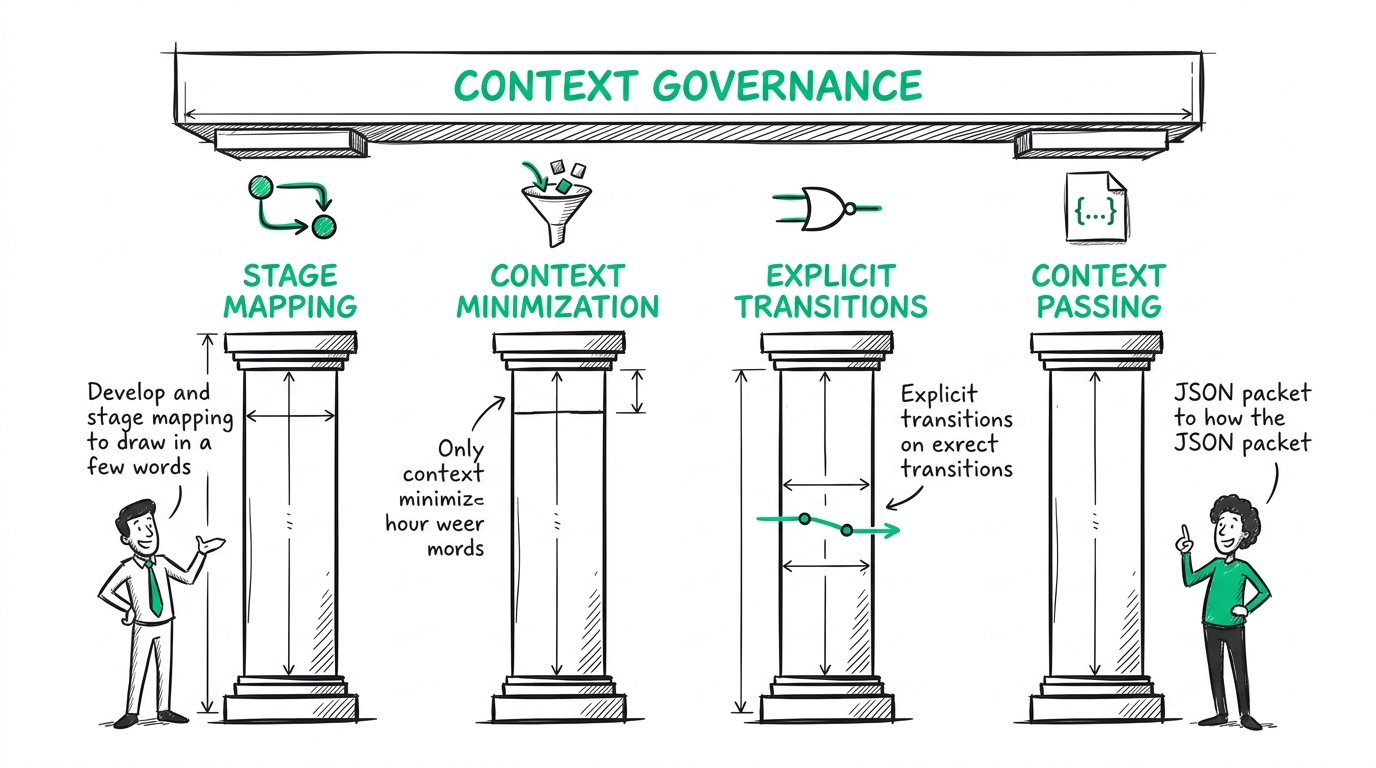
1. Stage Mapping (state machines, not text files)
Stop writing in text editors and start drawing. A conversation is a sequence of distinct states. You need to map your user journey as a strict state machine. "Authentication" is a stage. "Information Gathering" is a stage. "Action Execution" is a stage.
If you cannot visually draw your conversation as a graph with clear nodes and exit conditions, you do not understand your own product well enough to build it. Each stage has exactly one job. If a stage is trying to do three things, break it apart.
2. Context Minimization
This is the direct antidote to the "Lost in the Middle" problem. Once you have your stages mapped, you enforce a strict diet on the LLM.
When the user is in the "Checkout" stage, the LLM receives only the system instructions for processing a payment. It does not get the password reset policy. It does not get the company history. It doesn't even get the small-talk guidelines. You compress the context to the absolute minimum required to survive the immediate next turn. By starving the model of irrelevant information, you violently increase its adherence to the instructions that actually matter right now.
3. Explicit Transitions
This is where you kill the "Control Illusion." The LLM should never independently decide to change the state of the conversation.
If a user is in a troubleshooting flow and suddenly asks, "Actually, can I just get a refund?", the main generative model shouldn't be the one to pivot the logic. You use explicit routing — a separate, smaller classification model (like a semantic router) or a deterministic trigger that catches the intent shift, halts the current stage, and formally routes the user to the "Refund" stage. The transition is a hard system boundary, not an LLM interpolating a vibe shift. You control the gates.
4. Context Passing (structured memory)
So, if we aren't passing the entire raw chat transcript to the LLM on every single turn, how does it remember anything? It remembers through engineering.
When a user moves from Stage A (Gathering Info) to Stage B (Processing), you don't pass a giant string of "User said X, Assistant said Y." You extract the actual data and pass it as a structured payload. You pass a JSON object:
{ "user_authenticated": true, "issue_type": "hardware", "device_model": "iPhone 15" }You are passing state, not text. The LLM in Stage B wakes up, looks at this clean, structured data, reads its hyper-focused prompt, and executes its single job flawlessly.
This is what actual conversation architecture looks like. It's modular. It's testable. If the agent messes up a refund, you don't have to rewrite a 5,000-word monolith and pray you didn't break the greeting logic. You just go into the Refund stage, tweak the isolated context, and deploy.
It's closer to information architecture than to magic. Which is fine. I like information architecture. Now let's talk about what this actually looks like when you implement it in a real tool.
What Context Governance looks like in Bonsai
Talking about architecture in the abstract is easy, but eventually, you have to build the thing. If you want to see what Context Governance looks like in actual code, you can look at Bonsai, the headless conversational AI platform we recently open-sourced at utter.one.
We built Bonsai specifically because we were tired of watching "magical" demos turn into production nightmares. We realized that enterprises don't need raw model access; they need a governed system.
In Bonsai, you don't write a single system prompt. You don't even start with an LLM. You start by defining a Project, and inside that project, you define your Stages.
Here is how the architecture actually maps to reality:
1. True Stage Isolation
Instead of a monolithic text file, a Bonsai project is a literal state machine. Every Stage has its own isolated configuration. It has its own prompt template, its own enabled tools, and its own memory settings. If you are in the "Order Lookup" stage, the LLM is physically incapable of seeing the rules for the "Smalltalk" stage. The blast radius of any prompt tweak is strictly contained to that single node in your graph.
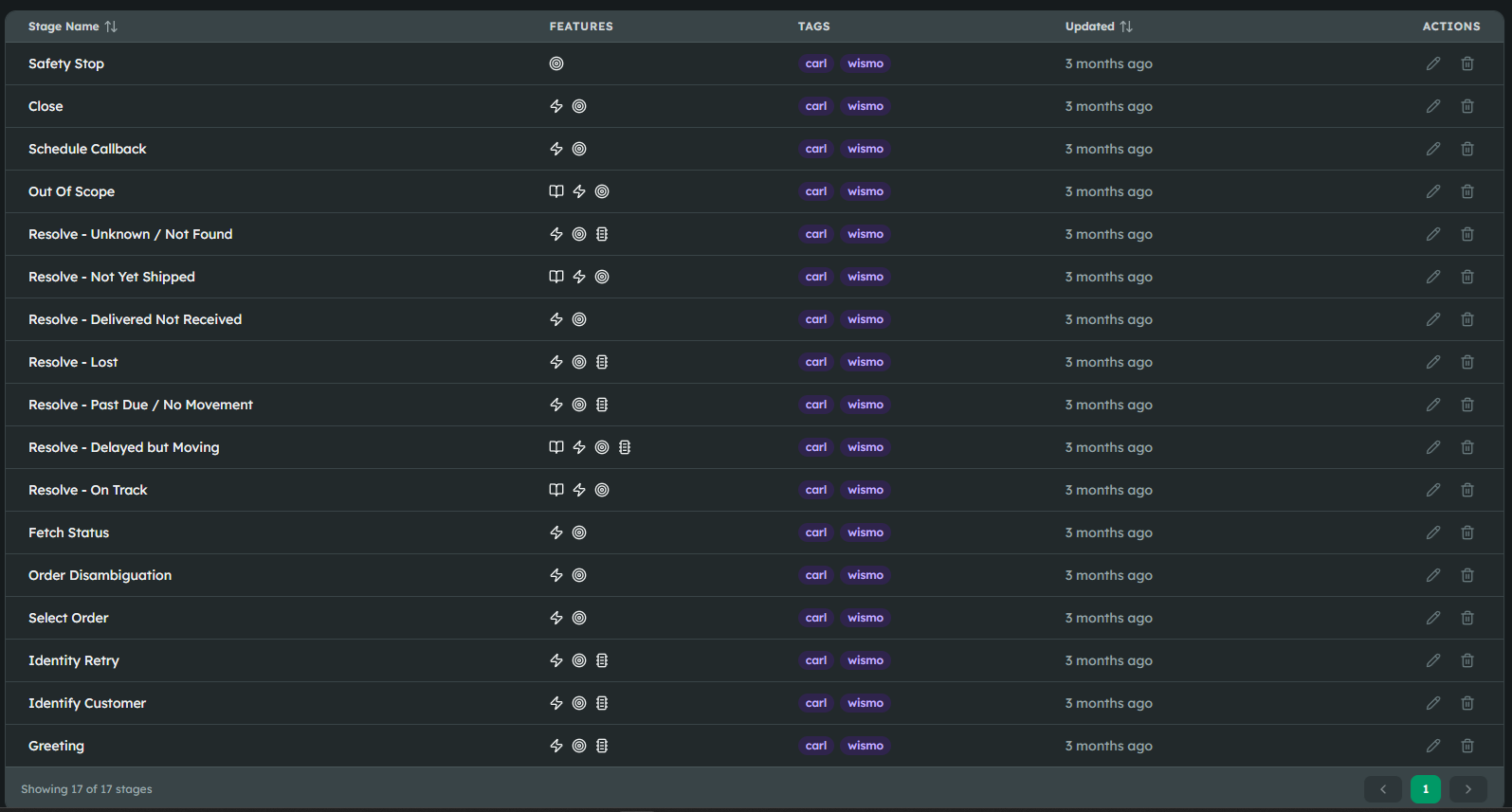
2. Deterministic Routing
We built Classifiers and Guardrails as first-class architectural components, not as prompt suggestions. When a user sends a message, it doesn't immediately go to the generative model. It hits the classification layer first. If a classifier detects that the user wants to cancel their subscription, the system triggers an explicit go_to_stage action. The LLM didn't decide to change the subject — the infrastructure routed the user deterministically.
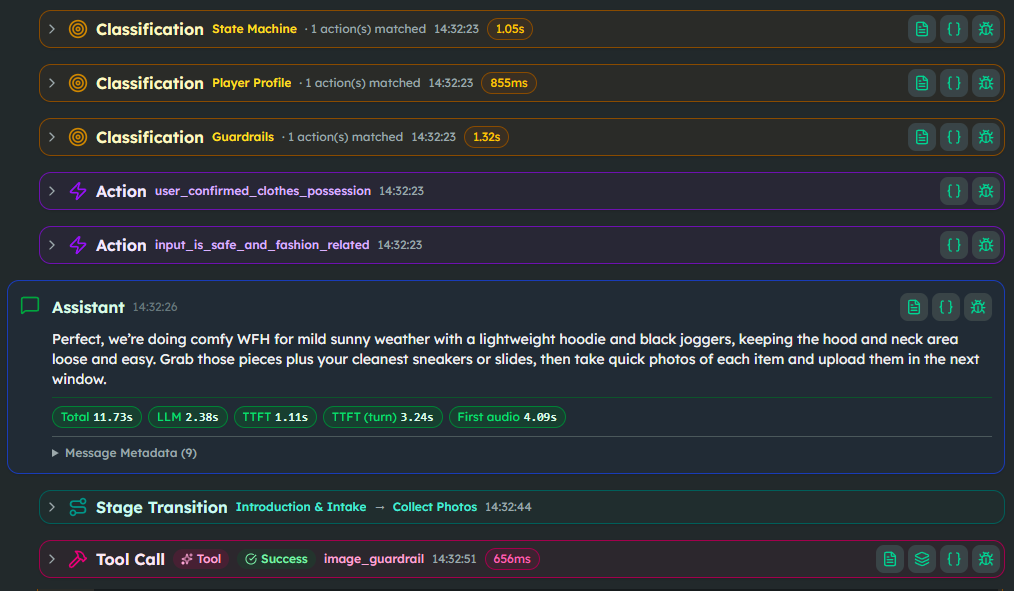
3. Context Transformers for State
This is how you kill the "Lost in the Middle" problem. Bonsai uses Context Transformers — small, hyper-focused extractions that run in parallel with the classifiers. Instead of passing 20 turns of raw chat history to the next stage, a Context Transformer extracts the exact JSON values you need (e.g., {"intent": "refund", "order_id": "12345"}). We update the structured User Profile or stage variables, and that clean data is what gets injected into the next stage. It's typed, queryable state management, not a messy transcript.
4. The Execution Pipeline
If you look at the Bonsai documentation, the lifecycle of a single conversational turn looks like this:
Input → Moderation → Classifiers + Guardrails + Transformers → Actions (webhooks, state updates, routing) → LLM Generation
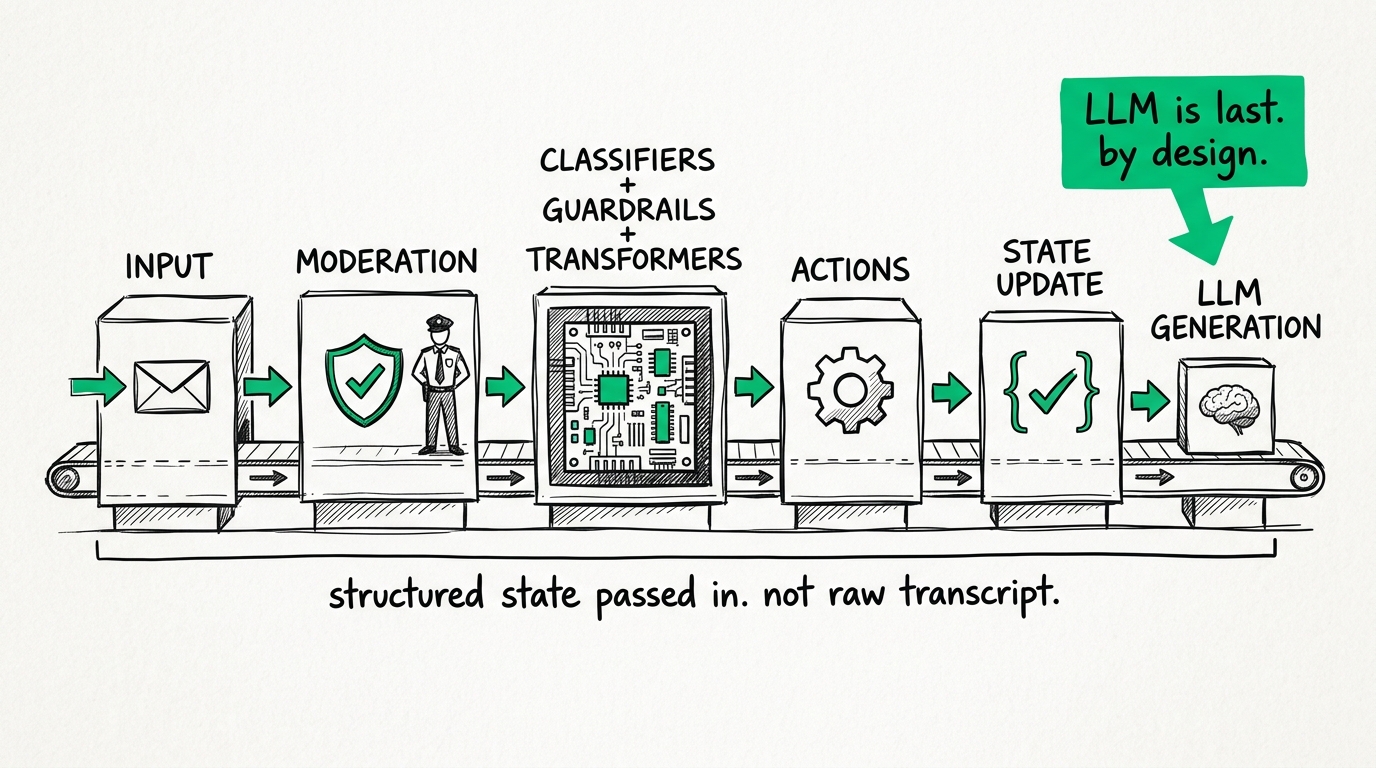
Notice where the LLM is. It's at the very end.
By the time the generative model is asked to speak, the system has already verified the guardrails, extracted the context, updated the state, and routed the user to the correct stage. The LLM is given a highly restricted, perfectly contextualized prompt, and all it has to do is generate a coherent response based on approved knowledge.
It works because we stop treating the LLM like an omniscient brain, and start treating it like a very powerful, somewhat erratic co-processor that needs strict API boundaries.
Worked example: the Lead Qualifier
Enough theory — here is a real Bonsai project we ship. The Lead Qualifier is a voice agent that runs sales discovery, decides whether the prospect is a fit, and — if they are — books a meeting and pushes everything into the CRM. It lives across two stages.
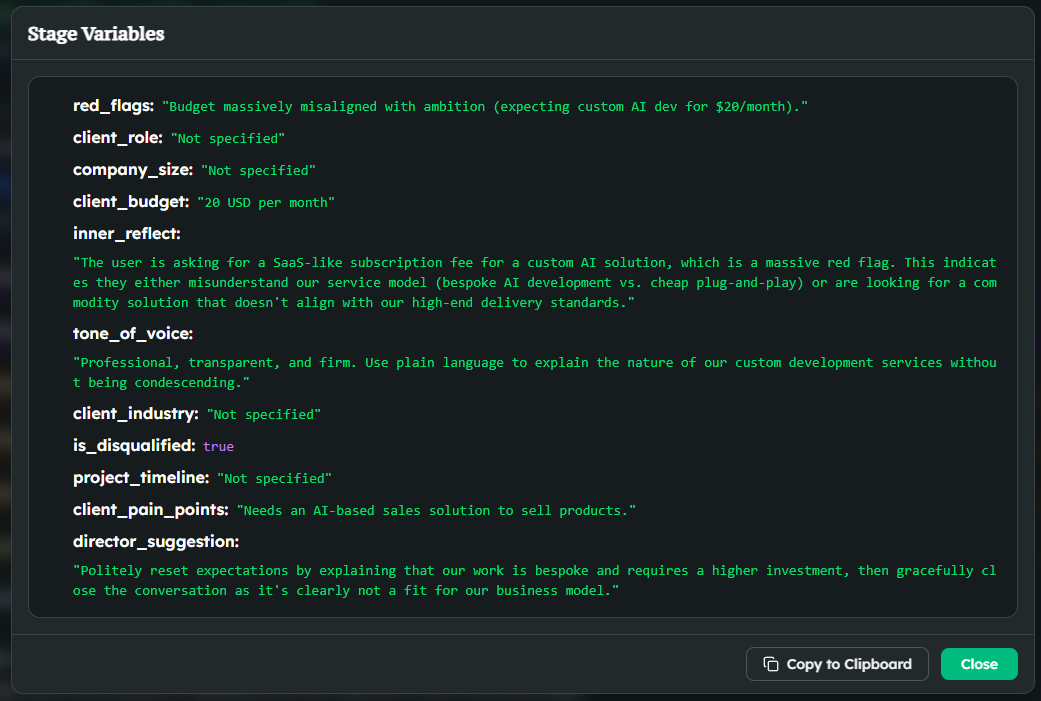
In the first stage, the agent's only job is to run a natural discovery conversation. The BANT rubric (Budget, Authority, Need, Timeline) sits in Constants, not in the system prompt — the qualification methodology is data, not narrative. The stage prompt only knows how to talk; the rubric lives next to it, queryable.
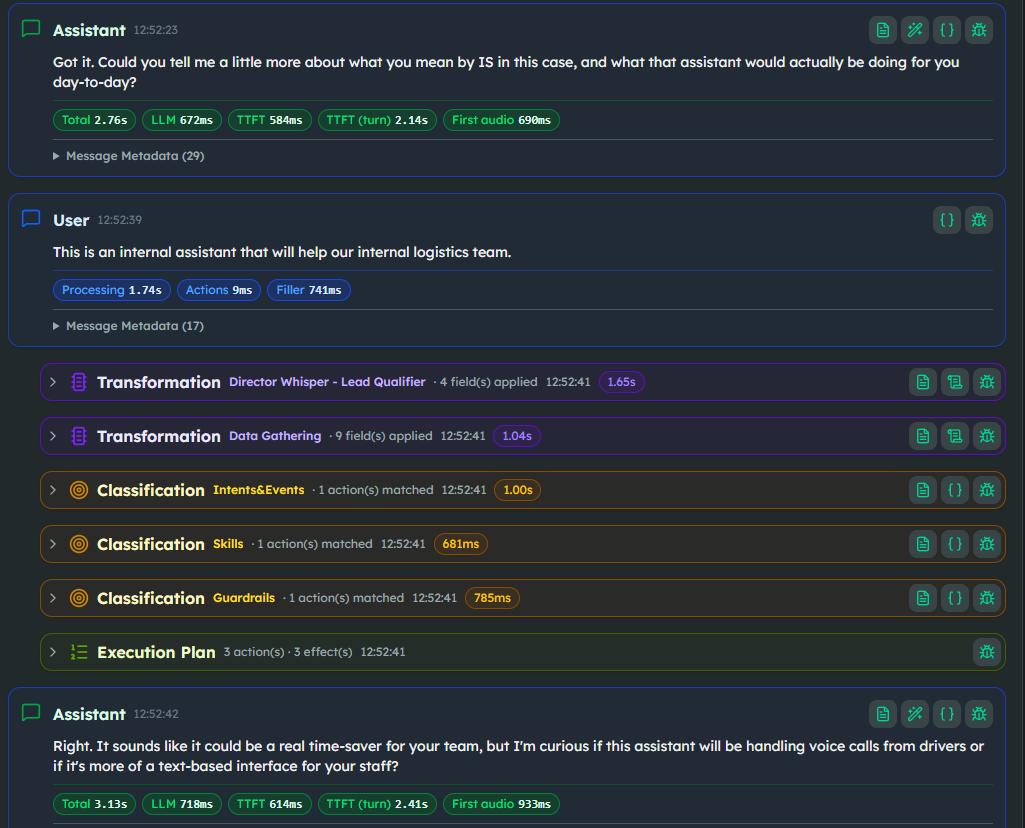
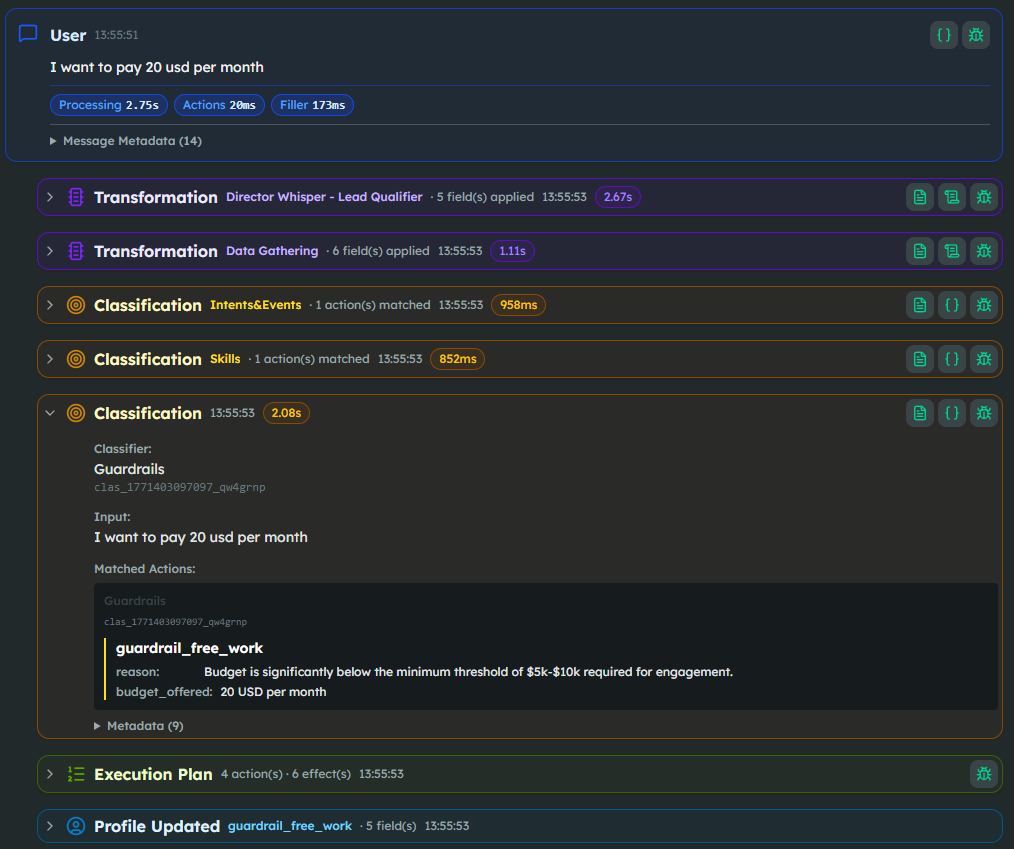
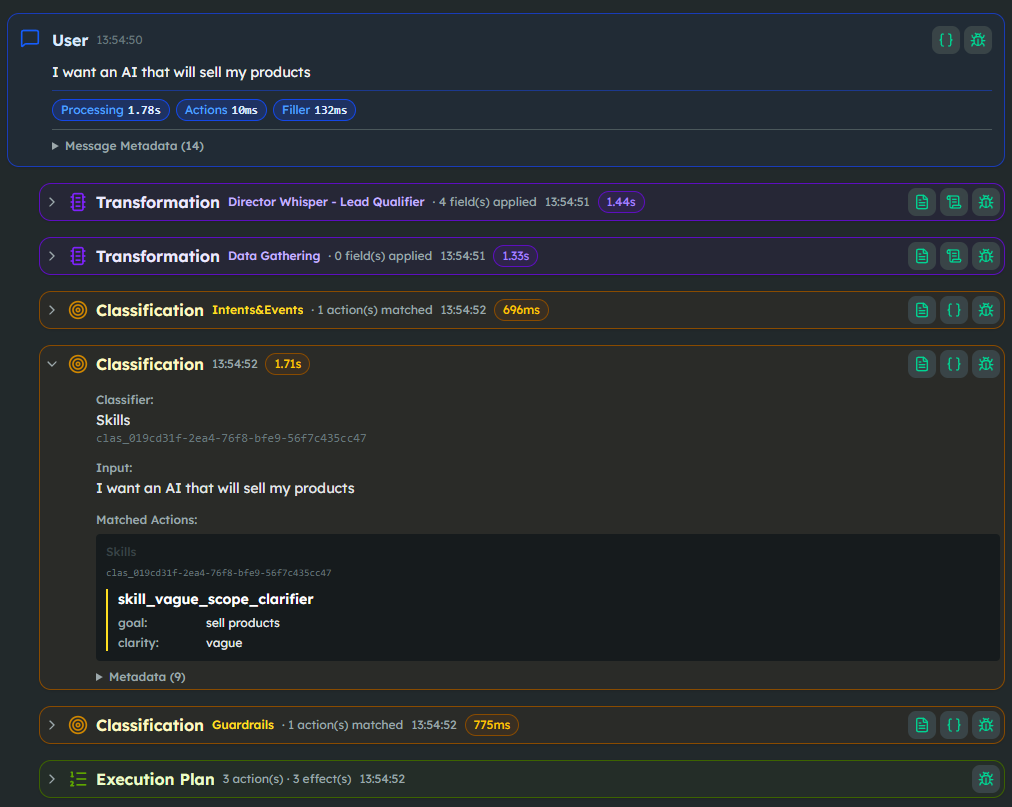
While that conversation unfolds, two transformers run on every turn. The Director Whisper extracts a coaching layer (inner_reflect, tone_of_voice, red_flags, director_suggestion) that the next turn's prompt consumes. Data Gathering pulls the actual BANT fields (client_budget, client_role, project_timeline, client_pain_points…) into the User Profile.
Two classifiers run in parallel. Guardrails catches free-work requests, sensitive projects, attempts to extract our BANT methodology itself, and the usual content moderation. Skills picks up softer cues — when a user says "I want an AI that will sell my products," the skill_vague_scope_clarifier fires and the next turn pivots into a clarification sub-flow without ever leaving the stage.
When the User Profile finally hits all data collected, an action fires go_to_stage("Book Call"). The second stage is mechanical: a Smart Function generates the user summary, a webhook pushes the contact to the CRM, the agent confirms a meeting slot, and a follow-up email goes out.
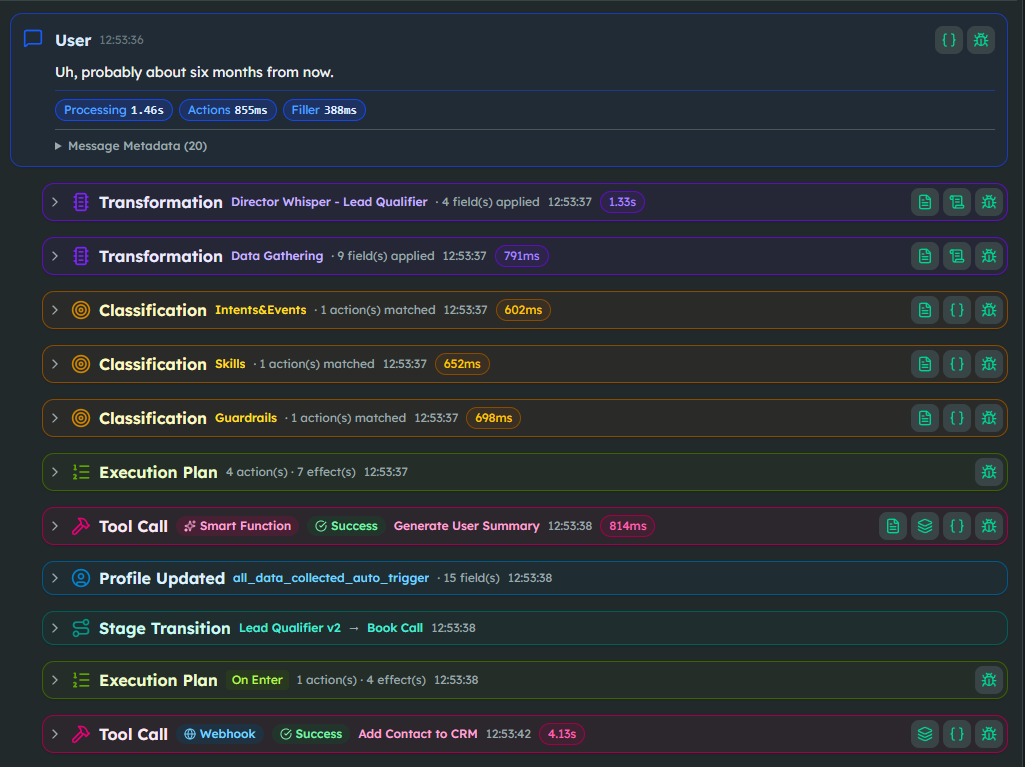
Notice what is never in the LLM prompt at any point: the full BANT rubric, the list of disqualifying conditions, the email template, the CRM payload schema. All of that lives in structure — Constants, Transformers, Guardrails, Webhooks. The LLM only ever sees the current stage's narrow prompt plus the structured state it actually needs to keep the conversation moving.
Stop writing prompts, start building systems
"AI is going to replace all human communication within 18 months."
I told you I don't say that. What I will say is that AI can handle highly complex, deeply frustrating, multi-turn human communication right now — but only if you respect the medium.
If you are treating your conversational AI like a magic text box where you can just endlessly append new IF/THEN rules, you are going to spend the next two years fighting hallucinations in QA. Your voice agents will drift, your users will hang up, and you'll blame the model.
Stop writing monolithic prompts. Draw your state machine. Isolate your context. Route deterministically. Start doing actual information architecture. It's less flashy than calling yourself a prompt wizard, but at least your system won't embarrass itself after turn three.